Download
MESH is developed on top of GraphX. In order to use MESH, you first need to apply Mesh-Patch on GraphX. Alternatively, you can download pre-compiled MESH-GraphX jar with MESH related changes from here.
You can access the MESH code from Github
Building MESH
We are currently supporting MESH only for Graphx 1.6. You can skip the MESH-GraphX section if you are using the prebuilt MESH-GraphX jar.
Prerequisites for building MESH:
- Unix-like environment ( We like and use Ubuntu )
- git
- Maven (we recommend version 3.3.9)
- Java 7 or 8
- Scala version 2.10.5
Building MESH-GraphX
Download Graphx from spark branch-1.6.
Patch for Graphx - Apply the patch on GraphX. Patch file can be accessed from here.
- git clone https://github.com/apache/spark.git
- cd spark
- git checkout branch-1.6
- git apply meshGraphx_branch-1.6.patch
To build GraphX jar, follow the documentation from Spark source, which can be accessed from here.
Building MESH-core
Add GraphX jar into the local maven repository. To do that, run:
where: path-to-file: Path to the graphx-JAR to install
MESH is built using Apache Maven. To built MESH and its examples, run:
How to run
Input
You can find an example input (csv file) here.
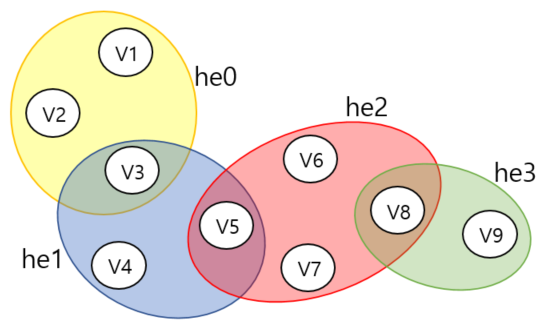
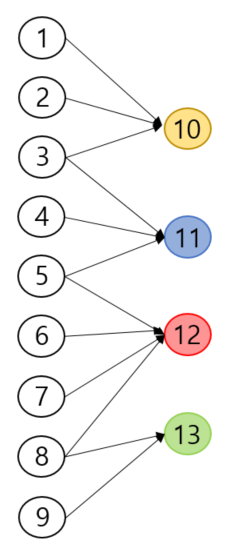
Element format is HyperedgeID, VertexID as shown in the example below.
0,1 0,2 0,3 1,3 1,4 1,5 2,5 2,6 2,7 2,8 3,8 3,9
The input elements represent a hypergraph (left) which is internally represented as a bipartite graph (right).
Output
You can find the initial and final values of hyperedges and vertices. You can also utilize your own logger to record your own logs such as partitioning or execution times as follow.
# User own logs INFO ShortestPathRunner: LOGGER,ShortestPathRunner,Start shortest path INFO ShortestPathRunner: LOGGER,ShortestPathRunner,Time taken for partitioning: 2327 ms # Initial values of hyperedges and vertices INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 4, attr: HyperVertexAttr(((),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 8, attr: HyperVertexAttr(((),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 12, attr: HyperEdgeAttr(((4,1),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 13, attr: HyperEdgeAttr(((2,1),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 1, attr: HyperVertexAttr(((),0.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 9, attr: HyperVertexAttr(((),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 5, attr: HyperVertexAttr(((),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 6, attr: HyperVertexAttr(((),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 10, attr: HyperEdgeAttr(((3,1),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 2, attr: HyperVertexAttr(((),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 11, attr: HyperEdgeAttr(((3,1),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 3, attr: HyperVertexAttr(((),Infinity)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Initial state - ID: 7, attr: HyperVertexAttr(((),Infinity)) # Final values of hyperedges and vertices INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 4, attr: HyperVertexAttr(((),2.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 8, attr: HyperVertexAttr(((),3.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 12, attr: HyperEdgeAttr(((4,1),3.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 13, attr: HyperEdgeAttr(((2,1),4.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 1, attr: HyperVertexAttr(((),0.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 9, attr: HyperVertexAttr(((),4.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 5, attr: HyperVertexAttr(((),2.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 6, attr: HyperVertexAttr(((),3.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 10, attr: HyperEdgeAttr(((3,1),1.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 2, attr: HyperVertexAttr(((),1.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 11, attr: HyperEdgeAttr(((3,1),2.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 3, attr: HyperVertexAttr(((),1.0)) INFO compute: LOGGER,BipartiteHyperGraph.compute,Final state - ID: 7, attr: HyperVertexAttr(((),3.0)) # User own logs INFO ShortestPathRunner: LOGGER,ShortestPathRunner,Time taken for run 1 : 1607 ms INFO ShortestPathRunner: LOGGER,ShortestPathRunner,End shortest path! Execution script
Execution script
#Input parameters : inputfile fileArg partitionStrategy numPartitions threshold numIters numRuns sourceId
Shortest Path Runner
package umn.dcsg.examples import dcsg.hg.Util._ import dcsg.hg.{CSV, HyperGraph} import org.apache.spark.graphx.PartitionStrategy._ object ShortestPathRunner { def main(args: Array[String]): Unit = { val logger = Logger("ShortestPathRunner") if (args.size != 8) { usage() println(args(0)) System.exit(1) } val inputfile = args(0) val fileArg = args(1).toInt var partitionStrategy = args(2) match { case "1D-src" => EdgePartition1D case "1D-dst" => EdgePartition1DByDst case "2D" => EdgePartition2D case "GreedySrc" => GreedySrc case "GreedyDst" => GreedyDst case "HybridSrc" => HybridSrc case "HybridDst" => HybridDst } val numPartitions = args(3).toInt val threshold = args(4).toInt val partition = Some(partitionStrategy -> (numPartitions, threshold)) val numIters = args(5).toInt val numRuns = args(6).toInt val sourceId = args(7).toInt val algorithm: HyperGraph[_, (Int, Int)] => Unit = ShortestPath.pr(_, numIters, sourceId) implicit val sc = makeSparkContext("ShortestPathRunner") try { val start = System.currentTimeMillis() val hg = CSV.hypergraph(inputfile, fileArg, partition) val end = System.currentTimeMillis() val partitionTime = end - start logger.log("Start shortest path") logger.log(s"Time taken for partitioning: $partitionTime ms") (1 to numRuns) foreach { i => val start = System.currentTimeMillis() algorithm(hg) val end = System.currentTimeMillis() val executionTime = end - start logger.log(s"Time taken for run $i : $executionTime ms") } logger.log("End shortest path!") } finally { sc.stop() } } def usage(): Unit = { println("usage: ShortestPathRunner inputfile fileArg partitionStrategy numPartitions threshold numIters numRuns outputFlag sourceId") } }